Introduction
Tutorial
用户指南
API Reference
SIF标准格式
成分分解
语法解析
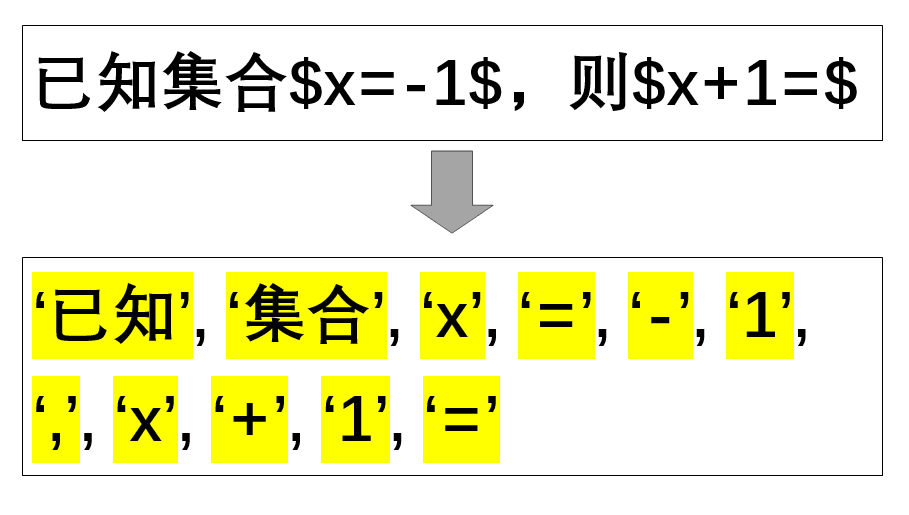
令牌化
预训练
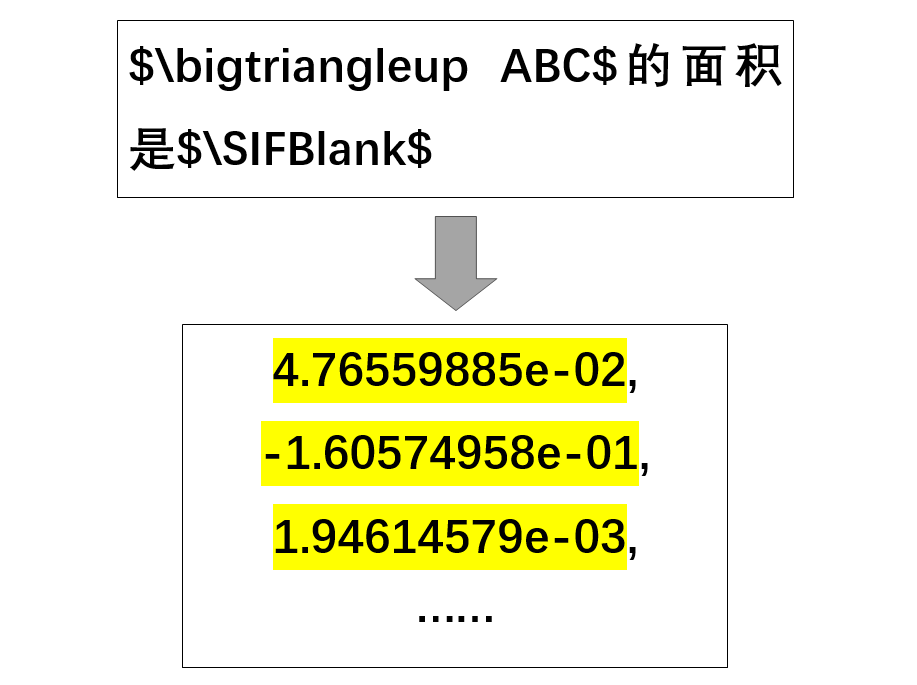
向量化
流水线
成分分解 :对符合SIF标准的试题进行分解,识别出题目中不同的成分(如文本、公式、图片等)。
语法解析 :对不同的成分进行个性化解析,包括公式解析、文本解析等,从而服务于后面的令牌化环节。
令牌化:根据成分分解和语法解析的结果,获取试题不同成分的令牌化序列,最终得到试题的多模态令牌序列。
向量化:将令牌序列送入预训练模型,得到试题相应的表征向量。
下游模型:将预训练模型得到的试题表征应用于各种下游任务(如难度预测、知识点预测、相似题检索等)。
为使您快速了解此项目的功能,此部分仅展示常用的函数接口使用方法(如得到令牌化序列、获取向量化表征等),对于其中间函数模块(如parse、segment、tokenize、formula等)以及更细分的接口方法不做展示,如需深入学习,请查看相关部分的文档。